第12章 正交编码与伪随机序列¶
第 12 章 正交编码与伪随机序列¶
正交编码与伪随机序列(pseudorandom sequence)在数字通信技术中都是十分重要的。正交编码不仅可以用作纠错编码,还可以用来实现码分多址通信,目前已经广泛用于蜂窝网中。伪随机序列在误码率测量、时延测量、扩谱通信、密码及分离多径等方面都有着十分广泛的应用。因此,本章将在简要讨论正交编码概念之后,着重讨论伪随机序列及其应用。
12.1 正交编码¶
12.1.1 正交编码的基本概念¶
首先说明正交的概念。若两个周期为 T 的模拟信号 \(s_{1}(t)\) 和 \(s_{2}(t)\) 互相正交,则有
同理,若 M 个周期为 T 的模拟信号 \(s_{1}(t)\) , \(s_{2}(t)\) , \(\cdots\) , \(s_{M}(t)\) 构成一个正交信号集合,则有
对于二进制数字信号,也有上述模拟信号这种正交性 (orthogonality)。由于数字信号是离散的,故可以把它看作是一个码组,并且用一数字序列表示这一码组。这里,我们只讨论二进制且码长相同的编码。这时,两个码组的正交性可用如下形式的互相关系数来表述。
设长为 n 的编码中码元只取值 +1 和 -1,以及 x 和 y 是其中两个码组:
其中, \(x_{i},y_{i}\in(+1,-1)\quad(i=1,2,\cdots,n)\) 。
则 x 和 y 间的互相关系数 (crosscorrelation coefficient) 定义为
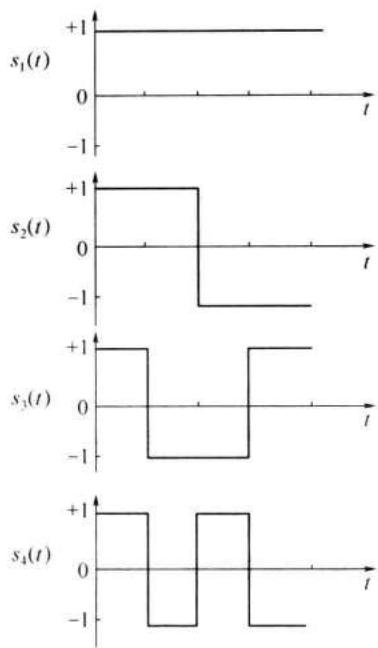
若码组 x 和 y 正交,则必有 \(\rho(x,y)=0\) 。例如,图 12-1 所示 4 个数字信号可以看作是如下 4 个码组:
按照式 \((12.1-5)\) 计算容易得知,这 4 个码组中任意两者之间的相关系数都为 0, 即这 4 个码组两两正交。我们把这种两两正交的编码称为正交编码。
类似上述互相关系数的定义,我们还可以对于一个长为 n 的码组 x 定义其自相关系数为
式中:x 的下标按模 n 运算,即有 \(x_{n+k} \equiv x_{k}\) 。
例如,设
则有
在二进制编码理论中,我们也常常采用二进制数字 “0” 和 “1” 表示码元的可能取值。这时,若规定用二进制数字 “0” 代替上述码组中的 “+1”, 用二进制数字 “1” 代替 “-1”, 则上述互相关系数定义式 (12.1-5) 将变为
式中:A 为 x 和 y 中对应码元相同的个数;D 为 x 和 y 中对应码元不同的个数。
例如,按照式 (12.1-8) 规定,式 (12.1-6) 中的例子可以改写成
第 12 章 正交编码与伪随机序列
将其代入式 \((12.1-8)\) ,计算出的互相关系数仍为 0。
式 (12.1-8) 中,若用 x 的 j 次循环移位代替 y, 就得到 x 的自相关系数 \(\rho_{x}(j)\) 。具体地讲,令
代入式 (12.1-8),就得到自相关系数 \(\rho_{x}(j)\) 。
在建立了正交编码的概念之后,我们进一步引入超正交码和双正交码的概念。我们知道,相关系数 \(\rho\) 的取值范围在 \(\pm1\) 之间,即有 \(-1\leqslant\rho\leqslant+1\) 。若两个码组间的相关系数 \(\rho<0\) , 则称这两个码组互相超正交 (super-orthogonal)。如果一种编码中任两码组间均超正交,则称这种编码为超正交编码。例如,在式 (12.1-9) 中,若仅取后三个码组,并且删去其第一位,构成如下新的编码:
则不难验证,由这三个码组所构成的编码是超正交码。
由正交编码和其反码便可以构成所谓双正交(duo - orthogonal)编码。例如,式 (12.1-9) 中正交码的反码 (inverse code) 为
式 \((12.1-9)\) 和式 \((12.1-11)\) 的总体即构成如下双正交码:
这种码中共有 8 种码组,码长为 4,任两码组间的相关系数为 0 或 - 1。
12.1.2 阿达玛矩阵¶
在正交编码理论中,阿达玛 (Hadamard) 矩阵具有非常重要的作用,因为它的每一行 (或列) 都是一个正交码组,而且通过它还很容易构成超正交码和双正交码,所以下面有
12.1 正交编码
必要对阿达玛矩阵加以讨论。
阿达玛矩阵是法国数学家 M. J. Hadamard 于 1893 年首先构造出来的,简记为 H 矩阵。它是一种方阵,仅由元素 +1 和 -1 构成,而且其各行 (和列) 是互相正交的。最低阶的 H 矩阵是 2 阶的,即
下面为了简单,把式 \((12.1-12)\) 中的 + 1 和 - 1 简写为 + 和 -, 这样式 \((12.1-12)\) 变为
阶数为 2 的幂的高阶 H 矩阵可以从下列递推关系得出,即
式中: \(N=2^{m}\) ; \(\otimes\) 为直积 (kronecker product)。
式 (12.1-14) 中直积是指将矩阵 \(H_{N/2}\) 中的每一个元素用矩阵 \(H_{2}\) 代替。例如:
上面给出几个 H 矩阵的例子,都是对称矩阵,而且第一行和第一列的元素全为 “+”。我们把这样的 H 矩阵称为阿达玛矩阵的正规形式,或称为正规阿达玛矩阵。
第 12 章 正交编码与伪随机序列
容易看出,在 H 矩阵中,交换任意两行,或交换任意两列,或改变任一行中每个元素的符号,或改变任一列中每个元素的符号,都不会影响矩阵的正交性质。因此,正规 H 矩阵经过上述各种交换或改变后仍为 H 矩阵,但不一定是正规的了。
按照式 (12.1-14) 递推关系可以构造出所有 \(2^{k}\) 阶的 H 矩阵。可以证明,高于 2 阶的 H 矩阵的阶数一定是 4 的倍数。不过,以 4 的倍数作为阶数是否一定存在 H 矩阵,这一问题并未解决。有人推测,对于所有 n=4t 都存在相应的 H 矩阵,但是这种推测尚未得到证明或者否定。目前,除 \(n=4\times47=188\) 外,所有 \(n\leqslant200\) 的 H 矩阵都已经找到。
H 矩阵中各行 (或列) 是相互正交的,所以 H 矩阵是正交方阵。若把其中每一行看作是一个码组,则这些码组也是互相正交的,而整个 H 矩阵就是一种长为 n 的正交编码,它包含 n 个码组。因为长度为 n 的编码共有 \(2^{n}\) 个不同码组,现在若只将这 n 个码组作为准用码组,其余 \((2^{n}-n)\) 个为禁用码组,则可以将其多余度用来纠错。这种编码在纠错编码理论中称为里德 — 缪勒 (Reed-Muller) 码。
12.1.3 沃尔什函数和沃尔什矩阵¶
我们知道,正弦和余弦函数可以构成一个完备正交函数系。由于正弦和余弦函数具有完备 (complete) 和正交性,所以由其构成的无穷级数或积分 (即傅里叶级数和傅里叶积分) 可以表示任一波形。类似地,由取值 “+1” 和 “-1” 构成的沃尔什 (Walsh) 函数也具有完备正交性,也可以用其表示任一波形。沃尔什函数可以用下列差分方程定义 \(^{[1]}\) :
式中:p=0 或 1, j=0, 1, 2, …;指数中的 \([j/2]\) 表示取 j/2 的整数部分。
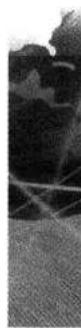
前 8 个沃尔什函数的波形示于图 12-2 中。从此图不难验证,其中任意两个沃尔什函数相乘积分的结果等于 0,即满足两两正交的条件。由于沃尔什函数的取值仅为 “+1” 和 “-1”,所以可以用其离散的抽样值表示成矩阵形式。例如,图 12-2 中的 8 个沃尔什函数可以写成如下沃尔什矩阵:
12.1
正交编码
由图 12-2 和式 (12.1-18) 可以看出,沃尔什矩阵是按照每一行中 “+1” 和 “-1” 的交变次数由少到多排列的。
沃尔什函数 (矩阵) 天生具有数字信号的特性,所以它们在数字信号处理和编码理论中有不小应用前景。目前在蜂窝网的码分多址体制中沃尔什函数就得到了实用。
除了阿达玛矩阵和沃尔什函数外,还有许多正交编码。例如,Haar 函数和 Paley 函数等 \(^{[1]}\) , 这里不再介绍。
12.2 伪随机序列¶
12.2.1 基本概念¶
在通信系统中的随机噪声会使模拟信
号产生失真和使数字信号出现误码,并且,它还是限制信道容量的一个重要因素。因此,人们经常希望消除或减小通信系统中的随机噪声。
另外,有时人们会希望获得随机噪声。例如,在实验室中对通信设备或系统性能进行测试时,可能要故意加入一定的随机噪声。又如,为了实现高可靠的保密通信,也希望利用随机噪声。为了上述目的,必须能够获得符合要求的随机噪声。然而,利用随机噪声的最大困难是它难以重复产生和处理。直至 20 世纪 60 年代,伪随机噪声的发明才使这一困难得到解决。
伪随机噪声具有类似于随机噪声的某些统计特性,同时又能够重复产生。由于它具有随机噪声的优点,又避免了随机噪声的缺点,因此获得了日益广泛的实际应用。目前广泛应用的伪随机噪声都是由周期性数字序列经过滤波等处理后得出的。在后面我们将这种周期性数字序列称为伪随机序列。它有时又称为伪随机信号和伪随机码。
12.2.2 \(m\) 序列¶
1. \(m\) 序列的产生¶
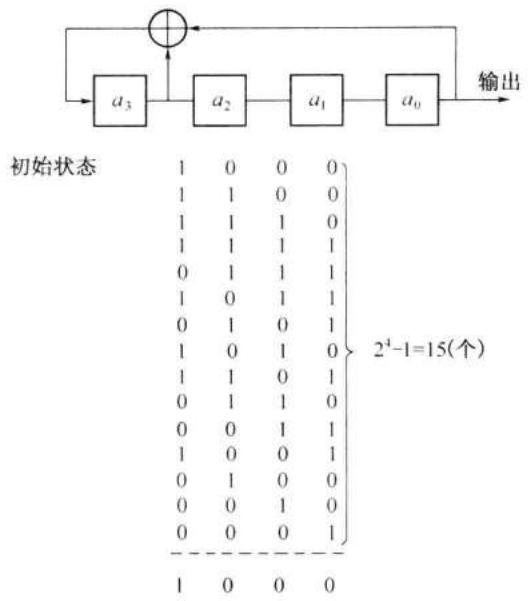
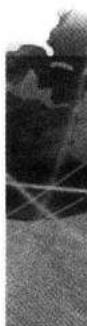
m 序列是最长线性反馈移位寄存器序列的简称。它是由带线性反馈的移存器产生的周期最长的序列。现在,我们先给出一个 m 序列的例子。在图 12-3 中示出一个 4 级线性反馈移存器。设其初始状态为 \((a_{3}, a_{2}, a_{1}, a_{0}) = (1, 0, 0, 0)\) ,则在移位一次时,由 \(a_{3}\) 和 \(a_{0}\) 模 2 相加产生新的输入 \(a_{4} = 1 \oplus 0 = 1\) ,新的状态变为 \((a_{4}, a_{3}, a_{2}, a_{1}) = (1, 1, 0, 0)\) 。这样移位 15 次后又回到初始状态 \((1, 0, 0, 0)\) 。不难看出,若初始状态为全 “0”,即 \((0, 0, 0, 0)\) ,则移位后得到的仍为全 “0” 状态。这就意味着在这种反馈移存器中应该避免出现全 “0” 状态,否则移存器的状态将不会改变。因为 4 级移存器共有 \(2^{4} = 16\) 种可能的状态。除全 “0” 状态外,只剩 15 种状态可用。这就是说,由任何 4 级反馈移存器产生的序列的周期
第 12 章 正交编码与伪随机序列
最长为 15。
我们常常希望用尽可能少的级数产生尽可能长的序列。由上例可见,一般来说,一个 n 级线性反馈移存器可能产生的最长周期等于 \((2^{n}-1)\) 。我们将这种最长的序列称为最长线性反馈移存器序列 (maximal length linear feedback shift register sequence), 简称 m 序列。反馈电路如何连接才能使移存器产生的序列最长,这就是本节将要讨论的主题。
图 12-4 为一般的线性反馈移存器原理方框图,图中各级移存器的状态用 \(a_{i}\) 表示, \(a_{i} = 0\) 或 \(1, i = \text{整数}\) 。反馈线的连接状态用 \(c_{i}\) 表示, \(c_{i} = 1\) 表示此线接通(参加反馈); \(c_{i} = 0\) 表示此线断开。不难推想,反馈线的连接状态不同,就可能改变此移存器输出序列的周期 \(p\) 。为了进一步研究它们的关系,需要建立几个基本的关系式。
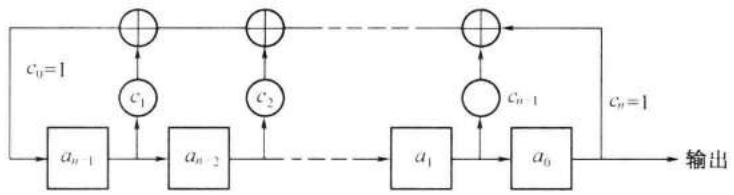
设一个 n 级移存器的初始状态为: \(a_{-1}a_{-2}\cdots a_{-n}\) ,经过 1 次移位后,状态变为 \(a_{0}a_{-1}\cdots a_{-n+1}\) 。经过 n 次移位后,状态为 \(a_{n-1}a_{n-2}\cdots a_{0}\) ,图 12-4 所示就是这一状态。再移位 1 次时,移存器左端新得到的输入 \(a_{n}\) ,按照图中线路连接关系,可以写为
因此,一般说来,对于任意一个输入 \(a_{k}\) ,有
12.2
伪随机序列
式 (12.2-2) 中求和仍为按模 2 运算。由于本章中类似方程都是按模 2 运算,故公式中不再每次注明 (模 2) 了。
式 (12.2-2) 称为递推方程 (recursive equation),它给出移位输入 \(a_{k}\) 与移位前各级状态的关系。按照递推方程计算,可以用软件产生 m 序列,不必用图 12-4 的硬件电路实现。
上面曾经指出,\(c_{i}\) 的取值决定了移存器的反馈连接和序列的结构,故 \(c_{i}\) 是一个很重要的参量。现在将它用下列方程表示:
这一方程称为特征方程 (characteristic equation)(或特征多项式)。式中 \(x^{i}\) 仅指明其系数 (1 或 0) 代表 \(c_{i}\) 的值,x 本身的取值并无实际意义,也不需要去计算 x 的值。例如,若特征方程为
则它仅表示 \(x^{0},x^{1}\) 和 \(x^{4}\) 的系数 \(c_{0}=c_{1}=c_{4}=1\) ,其余的 \(c_{i}\) 为 0,即 \(c_{2}=c_{3}=0\) 。按照这一特征方程构成的反馈移存器就是图 12-3 中所示的。
同样,我们也可以将反馈移存器的输出序列 \(\{a_{k}\}\) 用代数方程表示为
式 \((12.2-5)\) 称为母函数 (generating function)。
递推方程、特征方程和母函数就是我们要建立的三个基本关系式。下面的几个定理将给出它们与线性反馈移存器及其产生的序列之间的关系。
【定理 12-1】 \(f(x)\cdot G(x) = h(x)\) (12.2-6)
式中, \(h(x)\) 为次数低于 \(f(x)\) 的次数的多项式。
【证】将式 \((12.2-2)\) 代入式 \((12.2-5)\) ,得到
移项整理后,得到
将上式右端用符号 \(h(x)\) 表示,并因 \(c_{0} \equiv 1\) ,故上式变成
其中
第 12 章 正交编码与伪随机序列
再将式 \((12.2-3)\) 代入式 \((12.2-7)\) ,最后得出
在式 (12.2-8) 中,若 \(a_{-1}=1\) ,则 \(h(x)\) 的最高次项为 \(x^{n-1}\) ;若 \(a_{-1}=0\) ,则最高项次数 \(<(n-1)\) ,所以我们得知 \(h(x)\) 的最高项次数 \(\leqslant(n-1)\) ,而 \(f(x)\) 的最高项次数 = n,因为图 12-4 中已规定 \(c_{n}=1\) ,式 (12.2-3) 中最高项为 \(x^{n}\) 。故 \(h(x)\) 的次数必定低于 \(f(x)\) 的次数。【证毕】
【定理 12-2】一个 \(n\) 级线性反馈移存器之相继状态具有周期性,周期为 \(p \leqslant 2^n - 1\) 。
【证】线性反馈移存器的每一状态完全决定于前一状态。因此,一旦产生一状态 R,若它与以前的某一状态 Q 相同,则状态 R 后之相继状态必定和 Q 之相继状态相同,这样就可以具有周期性。
在 n 级移存器中,每级只能有两种状态: “1” 或 “0”。故 n 级移存器最多仅可能有 \(2^{n}\) 种不同状态。所以,在连续 \((2^{n} + 1)\) 个状态中必有重复。如上所述,一旦状态重复,就有周期性。这时周期 \(p \leqslant 2^{n}\) 。
若一旦发生全 “0” 状态,则后继状态也为全 “0”,这时的周期 \(p = 1\) 。因此,在一个长的周期中不能包括全 “0” 状态。所以周期 \(p \leqslant (2^n - 1)\) 。【证毕】
【定理 12-3】 若序列 \(A = \{a_k\}\) 具有最长周期 \((p = 2^n - 1)\) ,则其特征多项式 \(f(x)\) 应为既约多项式。
【证】所谓既约多项式是指不能分解因子的 (irreducible) 多项式。若一 \(n\) 次多项式 \(f(x)\) 能分解成两个不同因子,则可令
这样,式 (12.2-6) 可以写成如下部分分式 (partial fraction) 之和,即
式中: \(f_{1}(x)\) 的次数为 \(n_{1}, n_{1} > 0\) ; \(f_{2}(x)\) 的次数为 \(n_{2}, n_{2} > 0\) 。且有
令 \(G_{1}(x) = h_{1}(x) / f_{1}(x); G_{2}(x) = h_{2}(x) / f_{2}(x)\) ,则式 (12.2-9) 可以改写成
式 (12.2-12) 表明,输出序列 \(G(x)\) 可以看成是两个序列 \(G_{1}(x)\) 和 \(G_{2}(x)\) 之和,其中 \(G_{1}(x)\) 是由特征多项式 \(f_{1}(x)\) 产生的输出序列,\(G_{2}(x)\) 是由特征多项式 \(f_{2}(x)\) 产生的输出序列。而且,由定理 12-2 可知,\(G_{1}(x)\) 的周期 \(p_{1}\leqslant2^{n_{1}}-1,G_{2}(x)\) 的周期 \(p_{2}\leqslant2^{n_{2}}-1\) 。所以,\(G(x)\) 的周期 p 应是 \(p_{1}\) 和 \(p_{2}\) 的最小公倍数 LCM \([p_{1},p_{2}]\) , 即

12.2
伪随机序列
式 \((12.2-13)\) 表明,p 一定小于最长可能周期 \((2^{n}-1)\) 。
若 \(f(x)\) 可以分解成两个相同的因子,即上面的 \(f_{1}(x)=f_{2}(x)\) ,同样可以证明 \(p<2^{n}-1\) 。所以,若 \(f(x)\) 能分解因子,必定有 \(p<2^{n}-1\) 。【证毕】
【定理 12-4】一个 \(n\) 级移存器的特征多项式 \(f(x)\) 若为既约的,则由其产生的序列 \(A = \{a_k\}\) 的周期等于使 \(f(x)\) 能整除的 \((x^p + 1)\) 中最小正整数 \(p\) 。
【证】若序列 A 具有周期 p,则由式 (12.2-5) 和式 (12.2-6),得
式 \((12.2-14)\) 移项整理后,变成
由定理 12-1 可知,\(h(x)\) 的次数比 \(f(x)\) 的低,而且现已假定 \(f(x)\) 为既约的,所以式 (12.2-15) 表明 \((x^{p}+1)\) 必定能被 \(f(x)\) 整除。
应当注意,此时序列 A 之周期 p 与初始状态或者说与 \(h(x)\) 无关。当然,这里不考虑全 “0” 作为初始状态。
上面证明了若序列 A 具有周期 p,则 \((x^{p}+1)\) 必能被 \(f(x)\) 整除。另外,若 \(f(x)\) 能整除 \((x^{p}+1)\) ,令其商为
又因为在 \(f(x)\) 为既约的条件下,周期 p 与初始状态无关,现在考虑初始状态 \(a_{-1}=a_{-2}=\cdots=a_{-n+1}=0,a_{-n}=1\) ,由式 (12.2-8) 可知,此时有 \(h(x)=1\) 。故有
第 12 章 正交编码与伪随机序列
式 (12.2-17) 表明,序列 A 以 p 或 p 的某个因子为周期。若 A 以 p 的某个因子 \(p_{1}\) 为周期,\(p_{1}<p\) , 则由式 (12.2-15) 已经证明 \((x^{p_{1}}+1)\) 必能被 \(f(x)\) 整除。所以,序列 A 之周期等于使 \(f(x)\) 能整除的 \((x^{p}+1)\) 中最小正整数 p。【证毕】
在有了上述定理之后,我们还需要引入本原多项式 (primitive polynomial) 的概念。若一个 n 次多项式 \(f(x)\) 满足下列条件:
则称 \(f(x)\) 为本原多项式。
这样,由定理 12-4 就可以简单写出一个线性反馈移存器能产生 m 序列的充要条件为:反馈移存器的特征多项式为本原多项式。
【例】要求用一个 4 级反馈移存器产生 m 序列,试求其特征多项式。
这时,n=4,故此移存器产生的 m 序列的长度为 \(m=2^{n}-1=15\) 。由于其特征多项式 \(f(x)\) 应可整除 \((x^{m}+1)=(x^{15}+1)\) ,或者说,应该是 \((x^{15}+1)\) 的一个因子(factor),故我们将 \((x^{15}+1)\) 分解因子(factorize),从其因子中找 \(f(x)\) :
\(f(x)\) 不仅应为 \((x^{15}+1)\) 的一个因子,而且还应该是一个 4 次本原多项式。式 (12.2-18) 表明, \((x^{15}+1)\) 可以分解为 5 个既约因子,其中 3 个是 4 次多项式。可以证明,这 3 个 4 次多项式中,前 2 个是本原多项式,第 3 个不是。因为
这就是说, \((x^{4} + x^{3} + x^{2} + x + 1)\) 不仅可整除 \((x^{15} + 1)\) ,而且还可以整除 \((x^{5} + 1)\) ,故它不是本原的。于是,我们找到了两个 4 次本原多项式: \((x^{4} + x + 1)\) 和 \((x^{4} + x^{3} + 1)\) 。由其中任何一个都可以产生 \(m\) 序列,用 \((x^{4} + x + 1)\) 作为特征多项式构成的 4 级反馈移存器就是图 12-3 中给出的。
由上述可见,只要找到了本原多项式,我们就能由它构成 m 序列产生器。但是寻找本原多项式并不是很简单的。经过前人大量的计算,已将常用本原多项式列成表备查。在表 12-1 中列出了部分已经找到的本原多项式。在制作 m 序列产生器时,移存器反馈线 (及模 2 加法电路) 的数目直接决定于本原多项式的项数。为了使 m 序列产生器的组成尽量简单,我们希望使用项数最少的那些本原多项式。由表 12-1 可见,本原多项式最少有 3 项 (这时只需要用一个模 2 加法器)。对于某些 n 值,由于不存在 3 项的本原多项式,我们只好列入较长的本原多项式。
由于本原多项式的逆多项式也是本原多项式,例如,式 (12.2-18) 中的 \((x^{4}+x+1)\) 与 \((x^{4}+x^{3}+1)\) 互为逆多项式,即 10011 与 11001 互为逆码,所以在表 12-1 中每一本原多项式可以组成两种 m 序列产生器。
在一些书刊中,有时将本原多项式用八进制数字表示。我们也将这种表示方法示于

12.2
伪随机序列
表 12-1 中右侧。例如,对于 \(n = 4\) , 表中给出 “23”, 它表示

即 \(c_{0} = c_{1} = c_{4} = 1, c_{2} = c_{3} = c_{5} = 0\) 。
表 12-1 本原多项式表
| n | 本原多项式 | n | 本原多项式 | ||
| 代数式 | 八进制表示法 | 代数式 | 八进制表示法 | ||
| 2 | $x^{2} + x + 1$ | 7 | 14 | $x^{14} + x^{10} + x^{6} + x + 1$ | 42103 |
| 3 | $x^{3} + x + 1$ | 13 | 15 | $x^{15} + x + 1$ | 100003 |
| 4 | $x^{4} + x + 1$ | 23 | 16 | $x^{16} + x^{12} + x^{3} + x + 1$ | 210013 |
| 5 | $x^{5} + x^{2} + 1$ | 45 | 17 | $x^{17} + x^{3} + 1$ | 400011 |
| 6 | $x^{6} + x + 1$ | 103 | 18 | $x^{18} + x^{7} + 1$ | 1000201 |
| 7 | $x^{7} + x^{3} + 1$ | 211 | 19 | $x^{19} + x^{5} + x^{2} + x + 1$ | 2000047 |
| 8 | $x^{8} + x^{4} + x^{3} + x^{2} + 1$ | 435 | 20 | $x^{20} + x^{3} + 1$ | 4000011 |
| 9 | $x^{9} + x^{4} + 1$ | 1021 | 21 | $x^{21} + x^{2} + 1$ | 10000005 |
| 10 | $x^{10} + x^{3} + 1$ | 2011 | 22 | $x^{22} + x + 1$ | 20000003 |
| 11 | $x^{11} + x^{2} + 1$ | 4005 | 23 | $x^{23} + x^{5} + 1$ | 40000041 |
| 12 | $x^{12} + x^{6} + x^{4} + x + 1$ | 10123 | 24 | $x^{24} + x^{7} + x^{2} + x + 1$ | 100000207 |
| 13 | $x^{13} + x^{4} + x^{3} + x + 1$ | 20033 | 25 | $x^{25} + x^{3} + 1$ | 200000011 |
2. \(m\) 序列的性质¶
1)均衡性 (balance)¶
在 m 序列的一个周期中,“1” 和 “0” 的数目基本相等。准确地说,“1” 的个数比 “0” 的个数多一个。
【证】设一个 m 序列的周期为 \(m = 2^{n} - 1\) ,则此序列可以表示为
由于此序列中任何相继的 n 位都是产生此序列的 n 级移存器的一个状态,而且此移存器共有 m 个不同状态,所以可以把此移存器的这些相继状态列表,如表 12-2 所列。表中每一行为移存器的一个状态。m 个相继的状态构成此 m 序列的一个周期。由此表直接看出,最后一列的元素按自上而下排列次序就构成式 (12.2-20) 中的 m 序列。自然,其他各列也构成同样的 m 序列,只是初始相位不同。
因为表 12-2 中每一元素为一位二进制数字,即 \(a_i \in (0,1) (i=0,1,\cdots,(m-1))\) 。所以表中每一位移存器状态可以看成是一个 \(n\) 位二进制数字。这 \(m\) 个不同状态对应 \(1 \sim (2^n - 1)\) 间的 \(m\) 个不同的二进制数字。由于 1 和 \(m = (2^n - 1)\) 都是奇数,故 \(1 \sim (2^n - 1)\) 间这 \(m\) 个整数中奇数比偶数多一个。在二进制中,奇数的末位必为 “1”,偶数的末位必为 “0”,而此末位数字就是表 12-2 中最后一列。故表中最右列的相继 \(m\) 个二进制数字中 “1” 比 “0” 多一个。由于每列都构成一 \(m\) 序列,所以 \(m\) 序列中 “1” 比 “0” 多一个。
第 12 章 正交编码与伪随机序列
表 12-2 \(m\) 序列的相继状态
| $a_{n-1}$ | $a_{n-2}$ | ... | $a_2$ | $a_1$ | $a_0$ |
| $a_n$ | $a_{n-1}$ | ... | $a_3$ | $a_2$ | $a_1$ |
| $\vdots$ | $\vdots$ | ... | $\vdots$ | $\vdots$ | $\vdots$ |
| $a_{n+i-1}$ | $a_{n+i-2}$ | ... | $a_{i+2}$ | $a_{i+1}$ | $a_i$ |
| $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ | |
| $a_{n-2}$ | $a_{n-3}$ | ... | $a_1$ | $a_0$ | $a_{n-1}$ |
| $a_{n-1}$ | $a_{n-2}$ | ... | $a_2$ | $a_1$ | $a_0$ |
| $\vdots$ | $\vdots$ | ... | $\vdots$ | $\vdots$ | $\vdots$ |
2)游程分布¶
我们把一个序列中取值相同的那些相继的 (连在一起的) 元素合称为一个 “游程 (run)”。在一个游程中元素的个数称为游程长度。例如,在图 12-3 中给出的 m 序列可以重写为:
在其一个周期 (m 个元素) 中,共有 8 个游程,其中长度为 4 的游程有一个,即 “1111”, 长度为 3 的游程有一个,即 “000”, 长度为 2 的游程有两个,即 “11” 和 “00”, 长度为 1 的游程有 4 个,即两个 “1” 和两个 “0”。
一般说来,在 m 序列中,长度为 1 的游程占游程总数的 1/2;长度为 2 的游程占游程总数的 1/4;长度为 3 的游程占 1/8;…。严格讲,长度为 k 的游程数目占游程总数的 \(2^{-k}\) ,其中 \(1 \leqslant k \leqslant (n-1)\) 。而且在长度为 k 的游程中(其中 \(1 \leqslant k \leqslant (n-2)\) ),连 “1” 的游程和连 “0” 的游程各占一半。下面我们就来证明游程的这种分布规律。
【证】在表 12-2 中,每一行有 \(n\) 个元素。我们考虑恰好含有连续 \(k\) 个 “1” 的那些行,它们具有形状:
其中左侧 \((k + 2)\) 个元素中两端为 “0”,中间全为 “1”,这样就保证恰好含有连续 \(k\) 个 “1”,而右侧的 \((n - 2 - k)\) 个元素用 “\(\times\)” 表示,它们可以任意取值 “0” 或 “1”,不受限制。在表 12-2 的一个周期 \((m = 2^n - 1\) 行)中,符合式 (12.2-22) 形式的行的数目,按排列组合理论可知,等于 \(2^{n - 2 - k}\) 。由反馈移存器产生 \(m\) 序列的工作原理可知,形式如式 (12.2-22) 的一行中的 \(k\) 个 “1”,必定经过逐次位移最后输出,在输出序列中构成长度为 \(k\) 的一个连 “1” 游程。反之,输出序列中任何一个长度为 \(k\) 的连 “1” 游程,必然对应表 12-2 中这样的一行。所以,在 \(m\) 序列一个周期中长度为 \(k\) 的连 “1” 游程数目也等于 \(2^{n - k - 2}\) 。
同理,长度为 k 的连 “0” 游程数目也等于 \(2^{n-k-2}\) 。所以长度为 k 的游程总数 (包括连 “1” 和连 “0” 的两种游程) 为
在序列的每一周期中,长度在 \(1 \leqslant k \leqslant (n - 2)\) 范围内的游程所包含的总码元数为

12.2
伪随机序列
式 (12.2-24) 求和计算中利用了下列算术几何级数 (arithmetic geometric series) 公式:
因为序列的每一周期中共有 \((2^{n}-1)\) 个码元,所以除上述码元外,尚余 \((2^{n}-1)-(2^{n}-2n)=(2n-1)\) 个码元。这些码元中含有的游程长度,从表 12-2 观察分析可知,应该等于 n 和 \((n-1)\) ,即应有长为 n 的连 “1” 游程一个,长为 \((n-1)\) 的连 “0” 游程一个,这两个游程长度之和恰为 \((2n-1)\) 。并且由此构成的序列一个周期中,“1” 的个数恰好比 “0” 的个数多一个。
最后,我们得到,在每一周期中,游程总数为
计算式 (12.2-26) 求和时,利用了下列等比级数 (geometric series) 公式:
由式 \((12.2-23)\) 和式 \((12.2-26)\) 可知,长度为 k 的游程占游程总数的比例为
由于长度为 \(k = (n - 1)\) 的游程只有一个,它在游程总数 \(2^{n-1}\) 中占的比例为 \(1/2^{n-1} = 2^{-(n-1)}\) , 所以上式仍然成立。因此,可将上式改写为
长度为 k 的游程所占比例 \(=2^{-k}\) , \(1 \leqslant k \leqslant (n-1)\) (12.2-28)
【证毕】
3)移位相加特性¶
一个 \(m\) 序列 \(M_{p}\) 与其经过任意次延迟移位产生的另一个不同序列 \(M_{r}\) 模 2 相加,得到的仍是 \(M_{p}\) 的某次延迟移位序列 \(M_{s}\) ,即
我们现在分析一个 \(m = 7\) 的 \(m\) 序列 \(M_{p}\) 作为例子。设 \(M_{p}\) 的一个周期为 1110010。另一个序列 \(M_{r}\) 是 \(M_{p}\) 向右移位一次的结果,即 \(M_{r}\) 的一个相应周期为 0111001。这两个序列的模 2 和为
式 (12.3-30) 得出的为 \(M_{s}\) 的一个相应的周期,它与 \(M_{p}\) 向右移位 5 次的结果相同。下面我们对 m 序列的这种移位相加特性作一般证明。
第 12 章 正交编码与伪随机序列
【证】设产生序列 \(M_{p}\) 的 n 级反馈移存器的初始状态如图 12-4 所示。这一初始状态也就是表 12-2 中第一行的 \(a_{0}a_{1}a_{2}\cdots a_{n-1}\) 。由这一初始状态代入递推方程式 (12.2-2) 得到移存器下一个输入即
若将序列 \(M_{p}\) 的初始状态的 r 次延迟移位作为序列 \(M_{r}\) 的初始状态,则将 \(M_{r}\) 的初始状态 \(a_{r}a_{r+1}a_{r+2}\cdots a_{n+r-1}\) 代入递推方程式 (12.2-2),得到下一个输入:
将式 \((12.2-31)\) 和式 \((12.2-32)\) 相加 (模 2),得到
式 (12.2-33) 右端 \(n\) 个括弧中两元素模 2 相加的结果一定是表 12-2 中另一行的元素。这是因为表 12-2 中的各行包含了除全 “0” 外的全部 \(n\) 位二进制数字。设相加结果为
则式 \((12.2-33)\) 可以改写为
式(12.2-35)表明 \((a_{n} + a_{n + r})\) 仍为原 \(n\) 级反馈移存器按另一初始状态 \((a_{i + n - 1}a_{i + n - 2}\dots a_{i + 1}a_i)\) 产生的输入,这是因为 \(c_{1}c_{2}\dots c_{n}\) 未改变,移存器的反馈线接法也未改变。这个初始状态比 \(M_p\) 的初始状态延迟了 \(i\) 位。故序列 \(M_{p}\) 和 \(M_r\) 之和是 \(M_{p}\) 经过延迟 \(i\) 位的移位序列。 【证毕】
4)自相关函数¶
现在我们讨论 m 序列的自相关 (autocorrelation) 函数。由式 (12.1-8) 得知,m 序列的自相关函数可以定义为:
式中:A 为 m 序列与其 j 次移位序列一个周期中对应元素相同的数目;D 为 m 序列与其 j 次移位序列一个周期中对应元素不同的数目;m 为 m 序列的周期。
式 \((12.2-36)\) 还可以改写为
由 \(m\) 序列的延迟相加特性可知,式 (12.2-37) 分子中的 \(a_{i} \oplus a_{i+j}\) 仍为 \(m\) 序列的一个元素。所以上式分子就等于 \(m\) 序列一个周期中 “0” 的数目与 “1” 的数目之差。另外,由 \(m\) 序列的均衡性可知, \(m\) 序列一个周期中 “0” 的数目比 “1” 的数目少一个。所以式 (12.2-37) 分子等于 - 1。这样,就有
12.2
伪随机序列
当 \(j = 0\) 时,显然 \(\rho (0) = 1\) 。所以,我们最后写成
不难看出,由于 \(m\) 序列有周期性,故其自相关函数也有周期性,周期也是 \(m\) ,即
而且 \(\rho(j)\) 是偶函数,即有
上面数字序列的自相关函数 \(\rho(j)\) 只定义在离散的点上 (j 只取整数)。但是,若把 m 序列当作周期性连续函数求其自相关函数,则从周期函数的自相关函数的定义:
可以求出其自相关函数 \(R(\tau)\) 的表达式为 \(^{[2]}\)
式中: \(T_{0}\) 为 \(s(t)\) 的周期。
按照式 (12.2-38) 和式 (12.2-42) 画出的 \(\rho(j)\) 和 \(R(\tau)\) 的曲线示于图 12-5 中。图中的圆点表示 j 取整数时的 \(\rho(j)\) 取值,而折线是 \(R(\tau)\) 的连续曲线。可以看出,两者是重合的。由图还可以看出,当周期 \(T_{0}\) 非常长和码元宽度 \(T_{0}/m\) 极小时, \(R(\tau)\) 近似于冲激函数 \(\delta(t)\) 的形状。
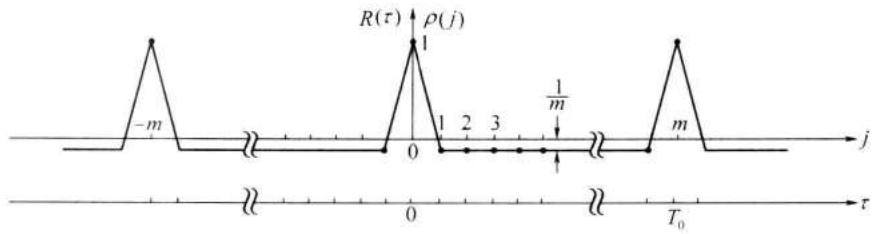
由上述可知, \(m\) 序列的自相关函数只有两种取值:0 和 \((1/m)\) 。有时我们把这类自相关函数只有两种取值的序列称为双值自相关序列。
5)功率谱密度¶
我们知道,信号的自相关函数与功率谱密度构成一对傅里叶变换。因此,我们很容易
第 12 章 正交编码与伪随机序列
对 m 序列的自相关函数 (式 (12.2-42)) 作傅里叶变换,求出其功率谱密度为 \(^{[2]}\)
按照式 (12.2-43) 画出的曲线示于图 12-6 中。由此图可见,在 \(T_{0}\rightarrow\infty\) 和 \(m/T_{0}\rightarrow\infty\) 时, \(P_{s}(\omega)\) 的特性趋于白噪声的功率谱密度特性。
6)伪噪声特性¶
我们对一正态分布白噪声抽样,若抽样值为正,则记为 “+”; 若抽样值为负,则记为 “-”。将每次抽样所得极性排成序列,例如:
这是一个随机序列,它具有如下三个基本性质:
由于 m 序列的均衡性、游程分布和自相关特性与上述随机序列的基本性质极相似,所以通常将 m 序列称为伪噪声 (PN) 序列,或称为伪随机序列。
但是,具有或部分具有上述基本性质的 PN 序列不仅只有 m 序列一种。m 序列只是其中最常见的一种。除 m 序列外,M 序列、二次剩余序列 (或称为 Legendre 序列)、霍尔 (Hall) 序列和双素数序列等都是 PN 序列。
12.2.3 其他伪随机序列简介¶
上面讨论的 m 序列由于具有很好的伪噪声性质,并且产生方法比较简单,所以受到广泛应用。不过,它有一个很大的缺点,就是其周期限制于 \((2^{n}-1)(n=1,2,3,\cdots)\) 。当 n 较大时,相邻周期相距较远,有时不能从 m 序列得到所需周期的伪随机序列。另外一些伪随机序列的周期所必须满足的条件与 m 序列的不同,因此可以得到一些其他周期的序列;即使周期与 m 序列相同,其结构也不一定相同。这些周期和结构不同的序列可以互相补充,提供我们选用。下面将简要介绍其中几种,它们都属于非线性反馈移存器序列。
12.2
伪随机序列
1. M 序列¶
由非线性反馈移存器产生的周期最长的序列称为 M 序列。它和上述 m 序列不同,后者是由线性反馈移存器产生的周期最长的序列。
由 12.2.2 节对 m 序列产生器的分析可知,一个 n 级 m 序列产生器只可能有 \((2^{n}-1)\) 种不同的状态。但是 n 级移存器最多可有 \(2^{n}\) 种状态,在 m 序列中不能出现的是全 “0” 状态。在线性反馈条件下,全 “0” 状态出现后,产生器的状态将不会再改变;但是在非线性反馈条件下,却不一定如此。因此,非线性反馈移存器的最长周期可达 \(2^{n}\) ,我们称这种周期长达 \(2^{n}\) 的序列为 M 序列。
目前,如何产生 M 序列的问题,尚未从理论上完全解决,人们只找到很少几种构造它的方法。下面仅简单介绍利用 m 序列产生器构成 M 序列产生器的方法。
我们首先观察图 12-3 中的例子。它是一个 \(n = 4\) 级的 \(m\) 序列产生器。图中给出了它的 15 种状态。若使它增加一个 “000” 状态,就可变成 \(M\) 序列产生器了。因为移存器中后级状态必须是由其前级状态移入而得,故此 “0000” 状态必须处于初始状态 “1000” 之前和 “0001” 状态之后。这就是说,我们需要将其递推方程修改为非线性方程,使 “0001” 状态代入新的递推方程后,产生状态 “0000”(而不是 “1000”),并且在 “0000” 状态代入后产生状态 “1000”(而不是保持 “0000” 不变)。
修改前的递推方程,由式 \((12.2-2)\) 给出:
为满足上述要求,修改后的递推方程应为
对于 n 级 m 序列产生器也一样。为使 n 级 m 序列产生器变成 M 序列产生器,也只需使其递推方程改为
有了递推方程,就不难构造出此 M 序列产生器。例如用这种方法得到的一个 4 级 M 序列产生器如图 12-7 所示。
M 序列与 m 序列类似,也在一定程度上具有噪声特性。它满足 m 序列的前两个性质:
第 12 章 正交编码与伪随机序列
\(1 \leqslant k \leqslant n - 2\) ; 长为 n 的游程有两个,没有长为 \((n - 1)\) 的游程。在同长的游程中,“0” 游程和 “1” 游程各占 1/2 。这两个性质的证明方法与 m 序列的一样。
但是,M 序列不再具有 m 序列的移位相加特性及双值自相关特性。
M 序列与 m 序列相比,最主要的优点是数量大,即同样级数 n 的移存器能够产生的平移不等价 M 序列总数比 m 序列的大得多,且随 n 的增大迅速增加。在表 12-3 中给出了级数 n 与可能产生的两种序列数目的比较。
| n级m序列和M序列数目比较 | ||||||||||
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| m序列数目 | 1 | 1 | 2 | 2 | 6 | 6 | 18 | 16 | 48 | 60 |
| M序列数目 | 1 | 1 | 2 | 16 | 2048 | $6.71088 \times 10^{7}$ | $1.44115 \times 10^{17}$ | $1.32922 \times 10^{36}$ | $2.26156 \times 10^{74}$ | $1.30935 \times 10^{151}$ |
M 序列的数量虽然相当大,但是目前能够实际产生出来的 M 序列数目却还不很多。这还有待于今后继续研究。
2. 二次剩余序列¶
所谓二次剩余又称平方剩余数,例如,\(3^{2}=9\) ;9 被 7 除得到的余数是 2, 即有
则称 2 为模 7 的平方剩余数。
一般说来,如果能找到一个整数 x, 它使
若此方程成立,我们就认为这个方程有解。满足此方程的 i 就是模 p 的二次剩余;否则,i 就是模 p 的二次非剩余。当规定 \(a_{0} = -1\) , 且
式中,p 为奇数,则称 \(\{a_{i}\}\) 为二次剩余序列, \(i=0,1,2,\cdots\) ,其周期为 p。
例如,设 p=19, 容易算出
12.2
伪随机序列
因此,1、4、5、6、7、9、11、16、17 是模 19 的二次剩余;而 2、3、8、10、12、13、14、15、18 是模 19 的非二次剩余。这样,得到周期 \(p = 19\) 的二次剩余序列为
式中: \(+ \equiv +1; - \equiv -1\) 。
这种序列具有 12.2.2 节中随机序列基本性质的第 (1) 条性质,但一般不具备第 (2) 条性质。当 p=4t-1 时 (t = 正整数), 它是双值自相关序列,即具有近于随机序列基本性质第 (3) 条的性质;当 \(p=4t+1\) 时,它不是双值自相关序列。但是若 p 很大,它仍具有近于第 (3) 条的性质。一般认为它也属于伪随机序列。
3. 双素数序列¶
上述二次剩余序列的周期 p 为素数 (prime)。在双素数序列中,周期 p 是两个素数 \(p_{1}\) 和 \(p_{2}\) 的乘积,而且 \(p_{2}=p_{1}+2\) ,即有
双素数序列 \(\{a_{i}\}\) 的定义为
其中
\((i,p)=1\) 表示 i 和 p 互为素数 (最大公因子为 1)。
例如,设 \(p_1 = 3, p_2 = 5, p = 3 \cdot 5 = 15\) 。这时在一个周期中满足 \((i, p) = 1\) 条件的 \(i\) ,即小于 15 且与 15 互素的正整数有 1、2、4、7、8、11、13、14。对于这些 \(i\) 值,可以计算出:
第 12 章 正交编码与伪随机序列
按照式 (12.2-54),对这些 \(i\) 值作 \(\left(\frac{i}{p_1}\right)\left(\frac{i}{p_2}\right)\) 的运算后,得出 \(a_1 = a_2 = a_4 = a_8 = 1\) 以及 \(a_7 = a_{11} = a_{13} = a_{14} = -1\) 。又因 \(i = 0 \equiv 5 = 10 (\bmod 5)\) ,故 \(a_0 = a_5 = a_{10} = 1\) 。对于其余的 \(i\) ,有 \(a_3 = a_6 = a_9 = a_{12} = -1\) 。所以此双素数序列为
式中: \(+ \equiv +1; - \equiv -1\) 。
可以验证,双素数序列也基本满足随机序列的基本性质,所以也属于 PN 序列。
12.3 扩展频谱通信¶
扩展频谱 (spread spectrum) 是指将信号的频谱扩展至占用很宽的频带,简称扩谱①。扩展频谱通信系统是将基带信号的频谱通过某种调制扩展到远大于原基带信号带宽的系统。例如,一个带宽为几千赫的话音信号,用振幅调制时,占用带宽仅为话音信号带宽的两倍;而在扩谱通信系统中,可能占用几兆赫的带宽。
扩谱技术一般可以分为三类: ①直接序列扩谱 (Direct-Sequence Spread Spectrum, DSSS), 它通常用一段伪随机序列 (又称为伪码) 表示一个信息码元,对载波进行调制。伪码的一个单元称为一个码片 (chip)。由于码片的速率远高于信息码元的速率,所以已调信号的频谱得到扩展。②跳频 (Frequency Hopping, FH) 扩谱,它使发射机的载频在一个信息码元的时间内,按照预定的规律,离散地快速跳变,从而达到扩谱的目的。载频跳变的规律一般也是由伪码控制的。③线性调频,在这种系统中,载频在一个信息码元时间内在一个宽的频段中线性地变化,从而使信号带宽得到扩展。由于此线性调频信号若工作在低频范围,则它听起来像鸟声 (chirp), 故又称 “鸟声” 调制。
扩谱通信的理论基础是香农 (Shannon) 的信道容量公式。它告诉我们,为达到给定的信道容量要求,可以用带宽换取信噪比,即在低信噪比条件下可以用增大带宽的办法无误地传输给定的信息。
扩谱通信的目的:①提高抗窄带干扰的能力,特别是提高抗有意干扰的能力,例如敌对电台的有意干扰。由于这类干扰的带宽窄,所以对于宽带扩谱信号的影响不大。②防止窃听。扩谱信号的发射功率虽然不是很小,但是其功率谱密度可以很小,小到低于噪声的功率谱密度,将发射信号隐藏在背景噪声中,使侦听者很难发现。此外,由于采用了伪码,窃听者不能方便地听懂发送的消息。③提高抗多径传输效应的能力。由于扩谱调制采用了扩谱伪码,它可以用来分离多径信号,所以有可能提高其抗多径的能力 (在后面将专门介绍分离多径信号的原理)。④使多个用户可以共用同一频带。在同一扩谱频带内,不同用户采用互相正交的不同扩谱码,就可以区分各个用户的信号,从而按照码分多址 (CDMA) 的原理工作。这种方案目前已经被广泛地应用于第三代蜂窝网中。⑤提供测距能力。通过测量扩谱信号的自相关特性的峰值出现时刻,可以从信号传输时间 (延迟) 的大小计算出传输距离。

12.3
扩展频谱通信
下面将仅就第一类扩谱技术,直接序列扩谱,作进一步的介绍。
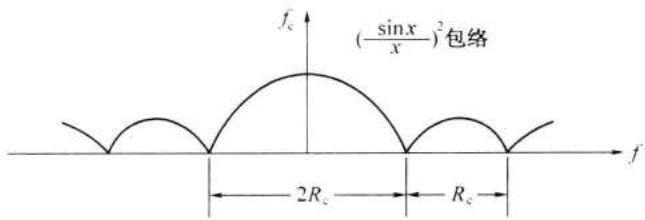
在直接序列扩谱系统中,是用一组伪码代表信息码元去调制载波。一般说来,可以采用任何一种调制方式,但是最常用的还是 2PSK。这种信号的典型功率谱密度曲线示于图 12-8 中。图中所示主瓣带宽 (零点至零点) 是伪码时钟速率 \(R_{c}\) 的 2 倍。每个旁瓣的带宽等于 \(R_{c}\) 。例如,若所用码片的速率为 5Mb/s, 则主瓣带宽将为 10MHz, 每个旁瓣宽为 5MHz。
直接序列扩谱通信系统原理方框图示于图 12-9 中。图中,二进制信码对载波进行反相键控。这个过程可以用相乘电路或平衡调制器实现。已调信号随即进行第二次调制。此时,用发送设备中产生的一个编 (伪) 码序列再次进行反相键控。此伪码序列的速率远高于信码速率。这次调制就起着扩谱的作用。由于信码和扩谱用的伪码都是二进制序列,而且是对同一载波进行反相键控,所以调制器实际上可以简化如图 12-10 所示,即先将两路编码序列模 2 相加,然后再去进行反相键控。已调信号可以直接传输或经过向上变频 (frequency conversion) 再送入信道传输。
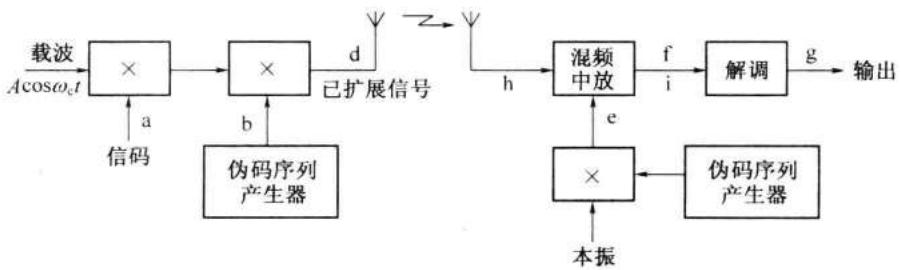
在接收端,先用与发送端同步的相同的伪码序列去反相键控本地振荡器,然后再用此已调本振去混频,就得到窄带的仅受信码调制的中频信号。它经过中频放大后就可以进入普通的相移信号解调器解调出信码。上述过程用图解方法示于图 12-11 中。图中每行图形在图 12-9 和图 12-10 中所处的位置已用各图形的编号标明。
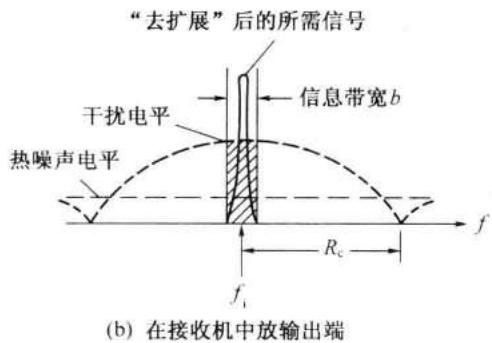
第 12 章 正交编码与伪随机序列
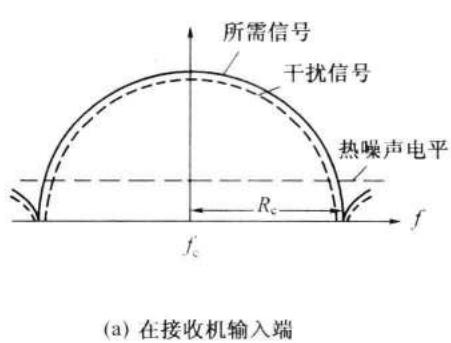
由图 12-11 可以看出,在收发两端的伪码序列产生器正确同步的时候,接收到的所需信号经过混频后 \(f\) 就恢复出仅受信码调相的窄带中频信号。而非所需的干扰信号 \(h\) ,经过混频后仍为宽带信号,因为它与接收机中的伪码序列不相关(或者说相关性很小)。这个宽带中频干扰信号经过中频放大器的带通滤波器滤波后,输出的干扰
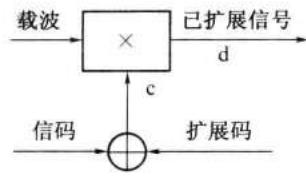
相对于信号电平是很小的。在图 12-12 中给出了所需信号和干扰信号在频域中的这种变化。
12.4 伪随机序列的其他应用¶
1. 分离多径技术¶
在短波电离层反射和对流层散射等通信系统中,以及在城市环境的移动通信网中,多径效应都比较严重。多径效应表现在一个发射信号可以经过多条路径到达接收点,并造成接收信号的衰落现象。衰落的原因在于每条路径的接收信号的相位不同。分离多径技术能够在接收端将多径信号的各条路径分离开,并分别校正每条路径接收信号的相位,使之按同相相加,从而克服衰落现象。而在分离多径技术中伪随机序列有重要作用。下面就来具体讨论这个问题。
12.4
伪随机序列的其他应用
The image is too blurry to recognize any text content.
[Non-Text]
为简单起见,我们先考察发射的一个数字信号码元。设这个码元是用 m 序列的一个周期去调制的余弦载波为
式中, \(M(t)\) 为一取值 \(\pm1\) 的 m 序列。
假设经过多径传输后,在接收机中频部分得到的输出信号为
其中共有 n 条路径的信号。第 j 条路径信号的振幅为 \(A_{j}\) ,延迟时间为 \(j\Delta\) ,载波附加的随机相位为 \(\varphi_{j}\) ,中频角频率为 \(\omega_{i}\) 。在此式中,忽略了各条路径共同的延迟,并且认为相邻路径的延迟时间差相等,均等于 \(\Delta\) 。在设计中我们选用此 \(\Delta\) 值作为 m 序列的一个码元宽度。
为了消除各条射线随机相位 \(\varphi_{j}\) 的影响,可以采用图 12-13 示出的自适应 (adaptive) 校相 (phase correction) 滤波器。设 \(s_{j}(t)\) 是式 (12.4-2) 中的第 j 条射线
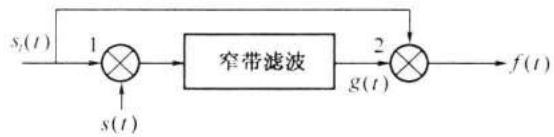
它加于图 12-13 中电路的输入端。此电路由两个相乘器和一个窄带滤波器组成。在第 1 个相乘器中, \(s_j(t)\) 与本地振荡电压 \(s(t) = \cos (\omega_0t + \varphi)\) 相乘。相乘结果通过窄带滤波器,后者的中心角频率为 \((\omega_{i} - \omega_{0})\) ,其通带极窄,只能通过 \((\omega_{i} - \omega_{0})\) 分量而不能通过各边带分量。故滤波输出 \(g(t)\) 在忽略一常数因子后可以表示为
在第 2 个相乘器中, \(s_j(t)\) 与 \(g(t)\) 相乘,取出乘积中差频项 \(f(t)\) ,仍忽略常数因子,可将 \(f(t)\) 表示为
在图 12-13 中省略了上述分离出差频项 \(f(t)\) 的带通滤波器。
由式 (12.4-5) 可见,经过自适应校相滤波器后,接收信号中的随机相位可以消除。上面只分析了一条路径接收信号的情况。当式 (12.4-2) 中多径信号输入此滤波器时,每条路径信号都同样受到相位校正,故使各路径信号具有相同的相位。这时的输出 \(f(t)\) 变为
此式中各路径信号的载波得到了校正,但是包络 \(M(t-j\Delta)\) 仍然有差别。为了校正各路径包络的相对延迟,可以采用图 12-14 所示的办法。此图中 AF 为自适应校相滤波器,抽头延迟线的抽头间隔时间为 \(\Delta\) 。为了说明简单起见,设现在共有 4 条路径的信号,n=4,抽头延迟线共有 3 段,每段延迟时间为 \(\Delta\) ,则相加器的输入信号包络如下:
第 12 章 正交编码与伪随机序列
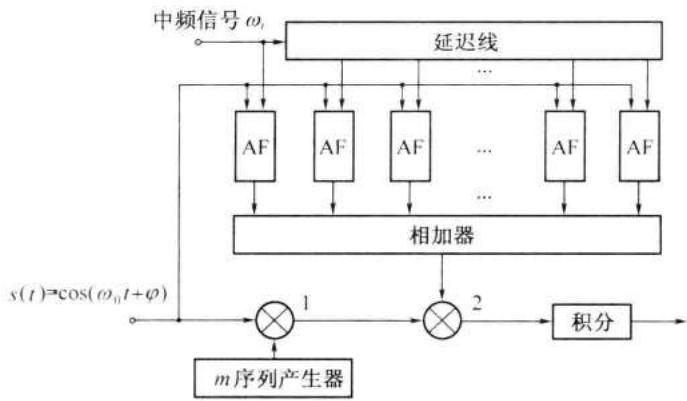
相加器输出信号的载波仍为 \(\cos(\omega_{0}t+\varphi)\) ,包络则为式 (12.4-7) 中各项之和。若图 12-14 中本地 m 序列产生器的输出为 \(M(t-3\Delta)\) ,则在相乘器 2 中与接收的多径信号相乘并经积分后,就能分离出包络为 \((A_{0}^{2}+A_{1}^{2}+A_{2}^{2}+A_{3}^{2})M(t-3\Delta)\) 的分量,即式 (12.4-7) 中右上至左下对角线上各项。或者说,相当于将 4 条路径的信号包络的相对延迟校正后相加了起来,而抑止掉了其余各项。
在数字通信系统中,为了传输不同的符号,可以采用不同的 m 序列。在接收端自然也需要有几个相应的 m 序列分别与之作相关检测。
2. 误码率测量¶
在数字通信中误码率是一项主要的质量指标。在实际测量数字通信系统的误码率时,一般说来,测量结果与信源送出信号的统计特性有关。通常认为二进制信号中 “0” 和 “1” 是以等概率随机出现的。所以测量误码率时最理想的信源应是随机序列产生器。这样测量的结果,我们认为是符合实际运用时的情况。
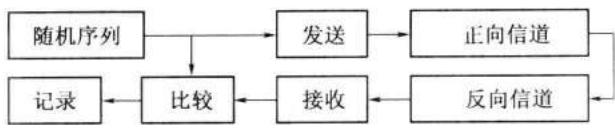
但是,用真正的随机序列产生器进行测量时,只适于闭环 (closed loop) 线路的测试,如图 12-15 所示。图中数字通信发送设备和接收设备放在同一地点,利用双向信道将发出的随机序列转回到本地,在比较器中将原发送随机序列和接收到的序列逐位比较。若两者不同,就认为出现了一个错码,送到记录设备中记录下来。
不过,这种闭环测试法所用的信道不符合实际情况,因为实际通信中一般都是单程传输信息的。在测量单程数字通信的误码率时,就不能利用随机序列,而只好用性能相近的伪随机序列代替它。图 12-16 示出这种情况。这时,发送设备和接收设备分处两地。由于发送端用的是伪随机序列,而且通常是 \(m\) 序列,接收端可以用同样的 \(m\) 序列产生器,由同步信号控制,产生出相同的本地序列。本地序列和接收序列相比较,就可以检测误码。

12.4
伪随机序列的其他应用

ITU 建议用于数据传输设备测量误码的 m 序列周期是 511,其特征多项式建议采用 \(x^{9} + x^{5} + 1\) ;以及建议用于数字传输系统(1544/2048 和 6312/8448kb/s)测量的 m 序列周期是 \(2^{15} - 1 = 32767\) ,其特征多项式建议采用 \(x^{15} + x^{14} + 1\) 。
3. 时延测量¶
有时我们需要测量信号经过某一传输路径所受到的时间延迟。例如,需要测量某一延迟线的时间延迟。另外,我们还常常通过测量一个无线电信号在某个媒质中的传播时间,从而折算出传播距离,即利用无线电信号测距。这就是说,这种测距的原理实质上也是测量延迟时间。
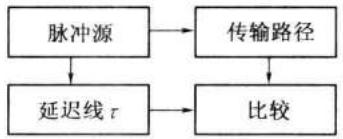
测量延迟的基本办法如图 12-17 (a) 所示。由脉冲源产生一周期性窄脉冲序列,其输出除了送入被测的传输路径外,还加到一个标准的可调延迟线。用比较电路去比较这两路输出脉冲的时间差。调节标准延迟线的延迟时间,使比较电路中两路脉冲同时到达,这时标准延迟线的延迟时间就等于被测传输路径的延迟时间。这种方法测量的最大延迟(距离)要受脉冲重复频率限制,测量的精确度也要受脉冲宽度(或上升时间)及标准延迟线的精确度限制。为了提高可测量的最大延迟(距离)和测量精确度,要求减小脉冲重复频率和脉冲宽度,这样会降低平均发送功率,影响远程测距时的作用距离。
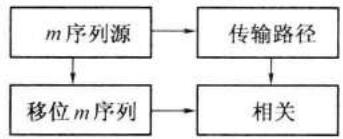
采用 m 序列代替周期性窄脉冲,用相关器代替比较器,如图 12-17 (b) 所示。这样,可以改善测量延迟的性能,克服上述方法中的缺点。这时,用一个移位的 m 序列与被测量的经过传输路径延迟的 m 序列相关。当两个序列的相位相同时,可以得到相关峰。由移位 m 序列与原 m 序列的相位差可以求得延迟时间。这种方法的测量精确度决定于所用 m 序列的一个码片的宽度,避免了原来方法中标准延迟线本身的误差。此外,用 m 序列代替窄脉冲,还可以使发送平均功率大大增加,提高了可测量的最大距离。自然,除 m 序列外,其他具有良好自相关特性的伪随机序列都可以用于测量时延。
第 12 章 正交编码与伪随机序列
在实际测距中,由于 m 序列源和相关器等是放在同一地点的,故图 12-17 (b) 中所示的传输路径长度应该是被测距离的两倍。
4. 噪声产生器¶
测量通信系统的性能时,常常要使用噪声产生器,由它给出具有所要求的统计特性和频率特性的噪声,并且可以随意控制其强度,以便得到不同信噪比条件下的系统性能。例如,在许多情况下,要求它能产生带限白高斯噪声。
使用噪声二极管这类噪声源做成的噪声产生器,在测量数字通信系统的性能时不很适用。因为它在一段观察时间内产生的噪声的统计特性,不一定和同样长的另一段观察时间内的统计特性相同。在一段较长的观察时间中,它的统计特性可能是服从高斯分布的,但在较短的一段观察时间中,其统计特性一般是不知道的。结果,测量得到的误码率常常很难重复得到。
m 序列的功率谱密度的包络是 \((\sin x/x)^{2}\) 形的。设 m 序列的码元宽度为 \(T_{1}\) ,则大约在 \(0 \sim (1/T_{1}) \times 45\% \text{ Hz}\) 的频率范围内,可以认为它具有均匀的功率谱密度。所以,可以用 m 序列的这一部分频谱作为噪声产生器的噪声输出,虽然这种输出是伪噪声,但是对于多次进行某一测量,都有较好的可重复性。
5. 通信加密¶
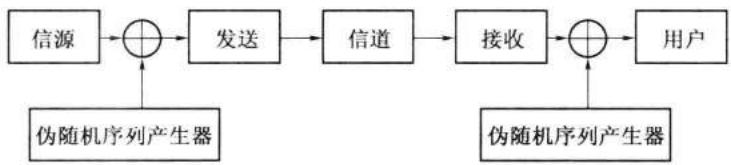
数字通信的一个重要优点是容易作到高度保密性的加密 (encryption)。在这方面伪随机序列十分有用。数字信号加密的基本原理可用图 12-18 表示。将信源产生的二进制数字消息和一个周期很长的伪随机序列模 2 相加,这样就将原消息变成不可理解的另一个序列。将这种加密序列在信道中传输,被他人窃听后也不可理解其内容。在接收端必须再加上一同样的伪随机序列,才能恢复为原发送消息。因为将此序列模 2 加入两次,就等于未加入。
在保密通信应用中, \(M\) 序列比 \(m\) 序列优越得多,因为前者的数目比后者的大很多。数目越多,为解密(decryption)所需要的搜索时间就越长。例如,由表 12-3 可见,在 \(n = 10\) 时, \(m\) 序列只有 60 个,而 \(M\) 序列的数目约达 \(1.3 \times 10^{151}\) 个。假定解密者用计算机搜索时,试探一种 \(M\) 序列平均需要 \(1\mathrm{ns}\) ,则平均约需 \((1.3 \times 10^{151}) / 2(365 \times 24 \times 60 \times 60 \times 10^9) = 2 \times 10^{134}\) 年才能破译这个密码。
12.4 伪随机序列的其他应用
6. 数据序列的扰乱与解扰¶
一般说来,数字通信系统的设计及其性能都与所传输的数字信号的统计特性有关。例如,我们在分析计算通信系统的误码率时,常假定信源送出的 “0” 和 “1” 码元是等概率的。在某些数字通信系统中,是从 “0” 和 “1” 码元的交变点提取位定时信息的,若经常出现长的 “0” 或 “1” 游程,则将影响位同步的建立和保持。如果数字信号具有周期性,则信号频谱中将存在离散谱线。由于电路中存在的不同程度的非线性,离散谱线有可能在多路通信系统其他路中造成串扰。为了限制这种串扰,常要求数字信号的最小周期足够长。
如果我们能够先将信源产生的数字信号变换成具有近似于白噪声统计特性的数字序列,再进行传输,在接收端收到这个序列后先变换成原始数字信号,再送给用户。这样就可以给数字通信系统的设计和性能估计带来很大方便。
所谓加扰 (scrambling) 技术,就是不用增加多余度而扰乱信号,改变数字信号统计特性,使其近似于白噪声统计特性的一种技术。这种技术的基础是建立在反馈移存器序列 (或伪随机序列) 的理论基础之上的。
采用加扰技术的通信系统组成原理如图 12-19 所示。在发送端用加扰器(scrambler) 来改变原始数字信号的统计特性,而接收端用解扰器 (descrambler) 恢复出原始数字信号。在图 12-20 中给出一种由 5 级移存器组成的自同步加扰器和解扰器的原理方框图。由此图可以看出,加扰器是一个反馈电路,解扰器是一个前馈 (feedforward) 电路,它们分别都是由 5 级移存器和两个模 2 加法电路组成。

设加扰器的输入数字序列为 \(\{a_{k}\}\) ,输出序列为 \(\{b_{k}\}\) ;解扰器的输入序列为 \(\{b_{k}\}\) ,输出序列为 \(\{c_{k}\}\) 。在这里,符号 \(\{a_{k}\}\) 表示二进制数字序列 \(a_{0}a_{1}a_{2}\cdots a_{k}a_{k+1}\cdots\) 。符号 \(\{b_{k}\}\) 和 \(\{c_{k}\}\) 均与此相仿。这样,由图 12-20 不难看出,加扰器的输出为
而解扰器的输出为
以上两式表明,解扰后的序列与加扰前的序列相同。
这种解扰器是自同步的,因为若信道干扰造成错码,它的影响至多持续错码位于移存器内的一段时间,即至多影响连续 5 个输出码元。
如果我们断开输入端,加扰器就变成一个反馈移存器序列产生器,其输出为一周期性序列。一般都适当设计反馈抽头的位置,使其构成为 m 序列产生器。因为它能最有效地将输入序列扰乱,使输出数字码元之间相关性最小。
加扰器的作用可以看作是使输出码元成为输入序列许多码元的模 2 和。因此可以把它当作是一种线性序列滤波器;同理,解扰器也可看作是一个线性序列滤波器。对于加扰器的级数和结构,ITU 有专门的建议给予规定。
第 12 章 正交编码与伪随机序列
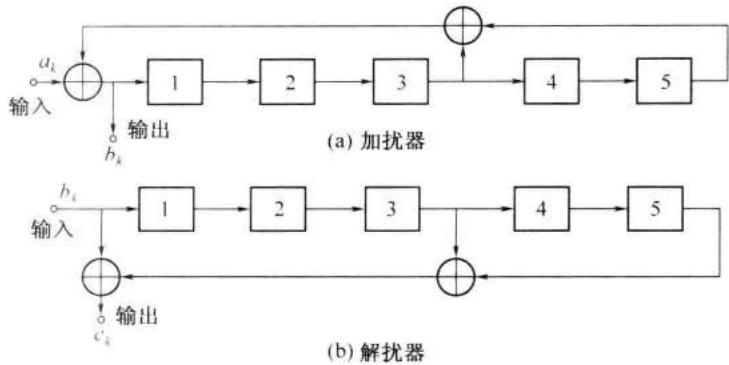
最后指出,上面 (图 12-18) 给出的加密方法,实际上也是一种加扰技术,也可以用来改变信号的统计特性。而这里讨论的加扰技术,在某种程度上也可以达到通信加密的目的。
12.5 小结¶
正交编码与伪随机序列在数字通信技术中都有十分重要的作用,它们广泛应用于码分多址通信、误码率测量、扩展频谱通信、密码、纠错编码和分离多径等领域中。
正交编码是由一组离散的正交函数构成的。正交编码中各个码组的相关系数均等于 0。阿达玛矩阵和沃尔什矩阵在正交编码中有着重要地位。
伪随机噪声可以具有类似于随机噪声的某些统计特性,同时又便于重复产生和处理。由于它具有随机噪声的优点,又避免了随机噪声的缺点,因此获得了日益广泛的实际应用。伪随机噪声都是由周期性伪随机序列经过滤波等处理后得出的。伪随机序列有时又称为伪随机信号和伪随机码。
m 序列是线性反馈最长移存器序列。由于 m 序列的均衡性、游程分布和自相关特性与随机序列的这些性质极相似,所以通常将 m 序列称为伪噪声(PN)序列或伪随机序列。m 序列是最主要的一种伪随机序列。递推方程、特征方程和母函数是设计和分析 m 序列产生器的三个基本关系式。一个线性反馈移存器能产生 m 序列的充要条件为:反馈移存器的特征方程为本原多项式。
在伪随机序列中 M 序列也有着重要地位,它是一种非线性反馈移存器序列。
扩展频谱调制是一类宽带调制技术,其中包括 DSSS、FHSS 和线性调频。但是前两种是最常用的体制。扩谱调制有许多优点,最主要的是抗干扰能力强和信号隐蔽。目前,其应用日益广泛。
多径分离技术是专门适用于扩谱信号的抗多径技术。它可以将接收信号中有害的从多径来的信号分量变成有用的多径信号分量,从而增强接收信噪比。
思考题¶
12-1 何谓正交编码?什么是超正交码?什么是双正交码?
12.5 小结
12-2 何谓阿达玛矩阵?它的主要特性如何?
12-3 何谓 \(m\) 序列?
12-4 何谓本原多项式?
12-5 线性反馈移存器产生 \(m\) 序列的充要条件是什么?
12-6 本原多项式的逆多项式是否也为本原多项式?为什么?
12-7 何谓 \(m\) 序列的均衡性?
12-8 何谓 “游程”?m 序列的 “游程” 分布的一般规律如何?
12-9 m 序列的移位相加特性如何?
12-10 为何 \(m\) 序列属于伪噪声(伪随机)序列?
12-11 何谓二次剩余序列?试举例说明之。
12-12 何谓 \(M\) 序列?它与 \(m\) 序列有何异同?
12-13 如何利用 \(m\) 序列来测量通信系统的误码率?
12-14 如何利用 \(m\) 序列来测量信号经过某一传输路径的时间延迟?
12-15 何谓通信加密?何谓数据加扰?它们有何异同?
12-16 何谓扩展频谱通信?它有何优点?
12-17 扩展频谱技术可以分为哪几类?
12-18 为何扩谱技术在加性高斯白噪声信道中不能使性能得到改善?
12-19 何谓 DSSS 通信系统?试画出其原理方框图。
12-20 何谓 FHSS 通信系统?它又可以分为哪两类?
12-21 FHSS 通信系统中通常采用相干调制还是非相干调制?为什么?
12-22 何谓分离多径技术?采用它的目的是什么?
12-23 试述自适应校相滤波器的功能。
习题¶
12-1 一个 3 级线性反馈移存器,已知其特征方程为 \(f(x) = 1 + x^{2} + x^{3}\) ,试验证它为本原多项式。
12-2 已知 3 级线性反馈移存器的原始状态为 111,试写出两种 \(m\) 序列的输出序列。
12-3 一个 4 级线性反馈移存器的特征方程为 \(f(x) = x^{4} + x^{3} + x^{2} + x + 1\) ,试证明由它所产生的序列不是 \(m\) 序列。
12-4 有一个由 9 级线性反馈移存器产生的 \(m\) 序列。试写出在每一周期内所有可能的游程长度的个数。
12-5 有一个由 9 级线性反馈移存器所组成的 \(m\) 序列产生器,其第 3、6 和 9 级移存器的输出分别为 \(Q_{3}, Q_{6}\) 和 \(Q_{9}\) ,试说明:
(1)将它们通过 “或” 门后得到一个新的序列,所得序列的周期仍为 \(2^{9}-1\) ,并且 “1” 的符号出现率约为 7/8。
(2)将它们通过 “与” 门后得到一个新的序列,所得序列的周期仍为 \(2^{9}-1\) ,并且 “1” 的符号出现率约为 1/8。
第 12 章 正交编码与伪随机序列
参考文献¶
